Selenium・Python・GoogleChromeを使って食べログで渋谷の一位の店の名前とURLを取得する(Seleniumインストール・XPATH)
Seleniumとは、GUI操作をコードで実行できるツール
本来はWebテスト目的っぽいが、
APIが提供されていないサイトでも操作を自動化できるし、何より定型作業をSeleniumでコード化しておけば仕事が捗る
API操作に比べて時間がかかるが、Seleniumが自動操作している間の時間を有効活用できる
今回は、食べログで渋谷駅1位のお店の名前とURLを取得してみる
API提供をしていないということは、多分「Webスクレイピングとかするなよ」ということだと思うので、Seleniumでの自動アクセスをやりすぎると怒られるかもしれません、自己責任でほどほどにお願いします
Seelniumのインストール
Pythonは今回3.8.7を使う
% python -V Python 3.8.7
Seleniumを使うにはインストールすべきものが2つ
SeleniumとWeb Driver
まずは、Seleniumをインストール
% pip install selenium
次にDriverをインストールするが、Driverはお使いのブラウザとバージョンを合わせる必要がある
今回自分は、Google Chromeを利用
Macの場合は、Google Chromeのバージョンは以下のコマンドで調べられるのでバージョンも調べておく
% /Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --version Google Chrome 103.0.5060.134
先程調べた、ブラウザと同じバージョンのDriverをインストールする
GoogleChromeの場合は、「chromedriver-binary」をインストールする
ドンピシャのバージョンがなければ、一個古いバージョンををインストールする
% pip install chromedriver-binary==103.0.5060.134
これで必要なものは揃った!
コード全体と実行結果
以下公式ドキュメントを参考に、やりたいことをコード化していく
https://selenium-python.readthedocs.io/getting-started.html#simple-usage
Seleniumは、基本的に、「find_element」で要素を指定して、指定した要素に対してクリックとかアクションを実行する、という段取りで操作する
要素を指定する方法はいくつかあるが、今回は一番簡単な「XPATHで指定する方法」を採用
- XPATHでの指定は、HTMLの階層フルパスを指定するものなので、GUI変更に弱いというデメリットもある
- もともとSeleniumはGUI操作をコード化するものなのでGUI変更に弱いが、IDやCSS_SELECTORで直接指定した方がXPATHで指定するよりマシかも
※ XPATH取得方法についてはこちら を参照ください
GoogleChromeでのXPATHの取得方法
コードの全体は以下
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import chromedriver_binary
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# ドライバ設定
options = Options()
options.add_argument('--headless') # ブラウザ画面を開かずに実行する
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(10) # クリックできるようになるまで待機する(暗黙的待機)
# tabelogを開く
driver.get("https://tabelog.com/")
# 渋谷を検索
element = driver.find_element(By.XPATH, "//*[@id='sa']")
element.send_keys("渋谷")
element.send_keys(Keys.RETURN)
# ランキングタブをクリック
element = driver.find_element(By.XPATH, "//*[@id='rstlst-access']/ul/li[2]/a")
element.click()
# 1位のお店の名前とURLを表示
element = driver.find_element(By.XPATH, "//*[@id='container']/div[15]/div[4]/div/div[6]/div[1]/div[2]/div/div[1]/div/div[3]/h3/a")
print(element.text)
print(element.get_attribute("href"))
出力結果は以下
% python selenium_work.py ラチュレ https://tabelog.com/tokyo/A1303/A130301/13198692/
コードの説明
それぞれやっていることをGUI画面と共に見ていく
必要モジュールをインポートした直後に最初にやっているのは、ドライバの設定
「implicitly_wait」はページがロードされるまで待機時間の設定
options = Options()
options.add_argument('--headless') # ブラウザ画面を開かずに実行する
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(10) # クリックできるようになるまで待機する(暗黙的待機)
ドライバの設定ができたらGUI操作をコード化していく
まずは、食べログのサイトを開く
driver.get("https://tabelog.com/")
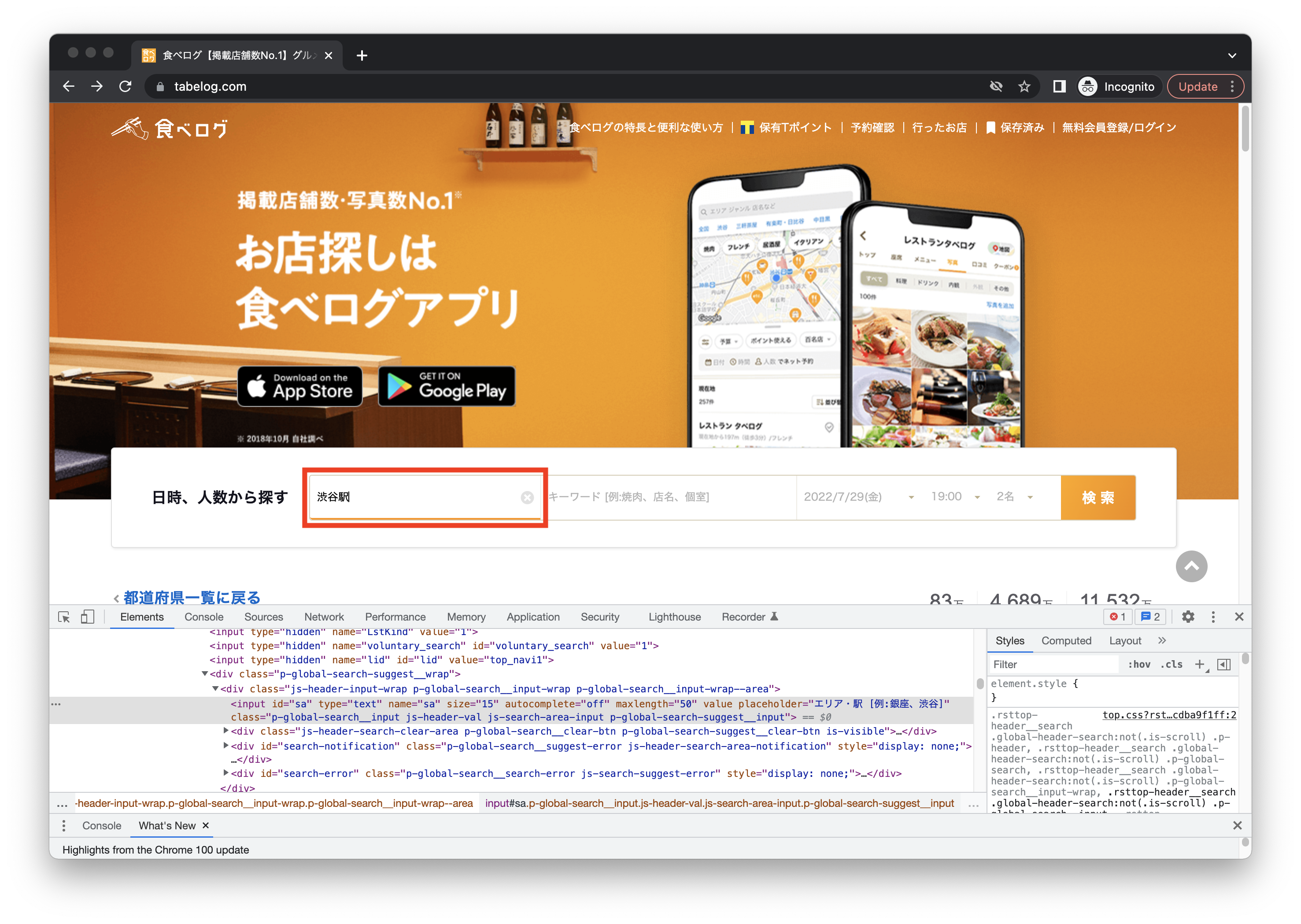
検索窓を指定し、「渋谷」と入力、エンターキーを押す
element = driver.find_element(By.XPATH, "//*[@id='sa']")
element.send_keys("渋谷")
element.send_keys(Keys.RETURN)
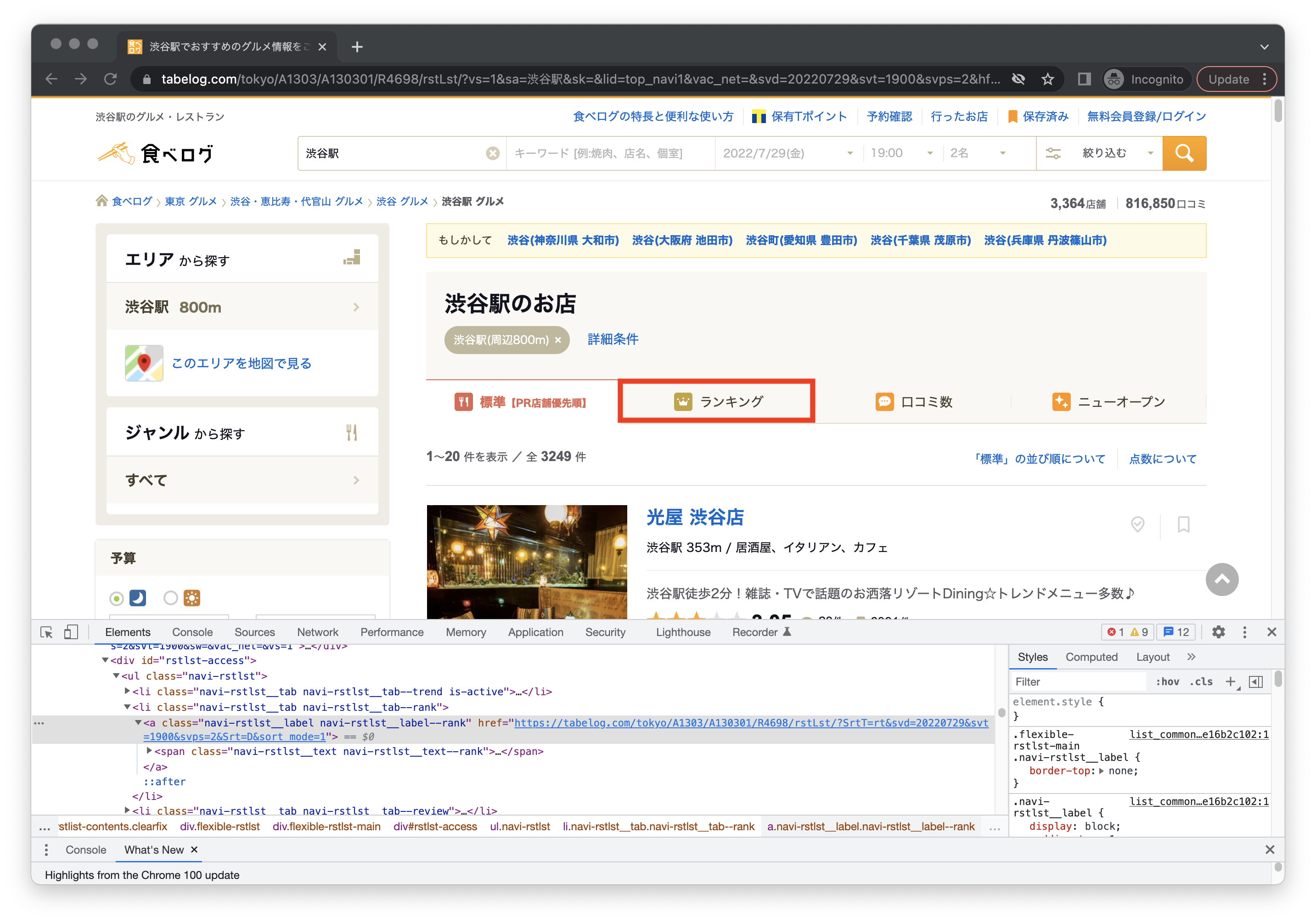
ランキングタブを指定してクリック
element = driver.find_element(By.XPATH, "//*[@id='rstlst-access']/ul/li[2]/a") element.click()
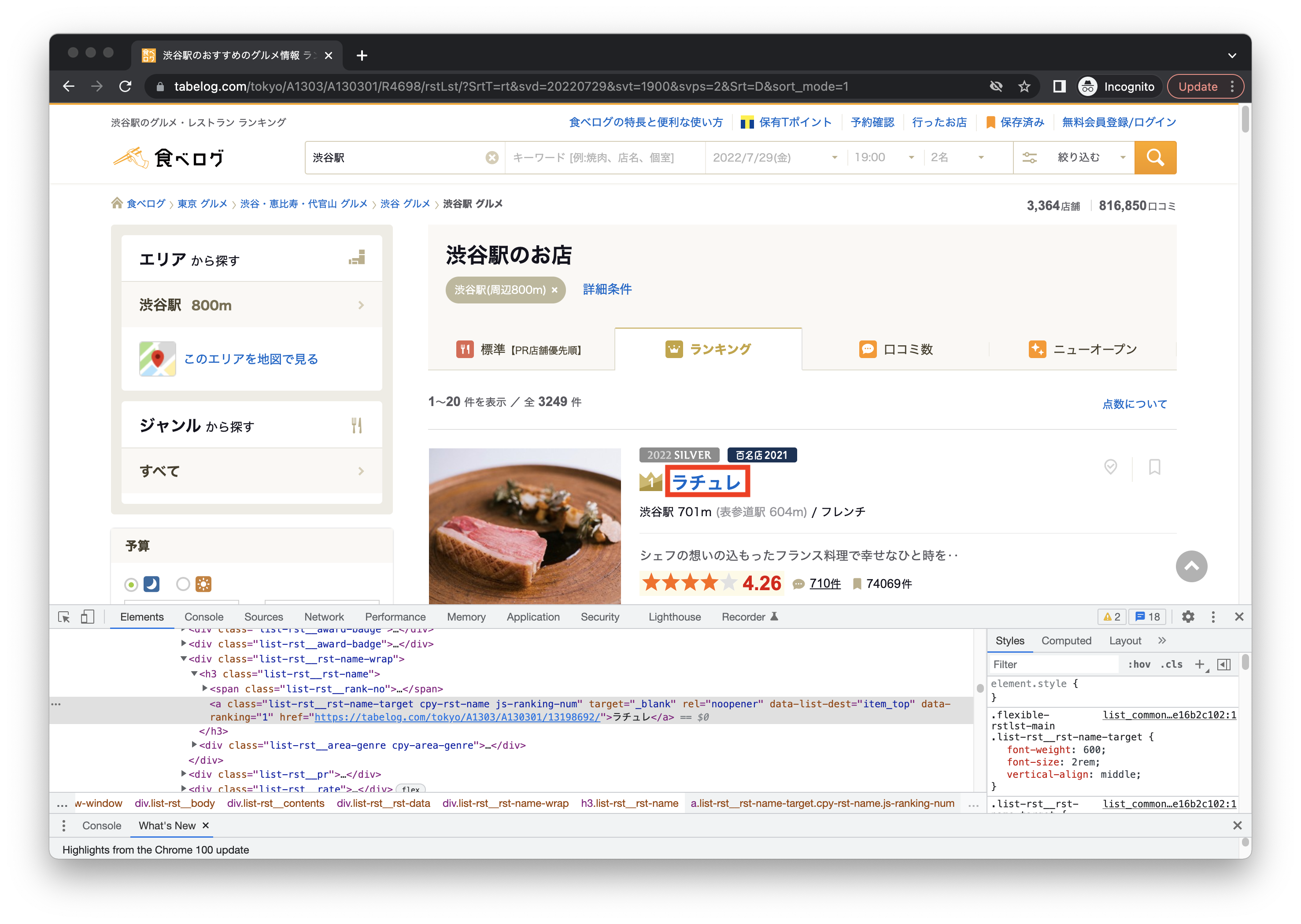
検索結果が表示されたら、1位のお店の名前とURLをPrintする
element = driver.find_element(By.XPATH, "//*[@id='container']/div[15]/div[4]/div/div[6]/div[1]/div[2]/div/div[1]/div/div[3]/h3/a")
print(element.text)
print(element.get_attribute("href"))
以上。