この記事は3年以上前に書かれた記事で内容が古い可能性があります
Jupyterをインストールしたのでcsvとjsonデータをpandasとmatplotlibで分析してみる
Jupyterをインストールしたので活用する
今回使うデータは、「Trending YouTube Video Statistics」
Kaggleのページから取ってくる(会員登録が必要)
https://www.kaggle.com/datasnaek/youtube-new
% jupyter notebook
と打ったディレクトリと同じ階層に取ってきたデータを配置する
今回は、USのデータのみ使う
% tree . ├── 20190323_Kaggle_Youtube.ipynb ├── US_category_id.json ★これと ├── USvideos.csv ★これ
データを配置したので、新しいノートを作成する
まずは、「New」>「Notebook」>「Python3」をクリック
csv/jsonデータを読み込む
Terminalでpandasをインストール
% pip install pandas
Jupyter画面で操作
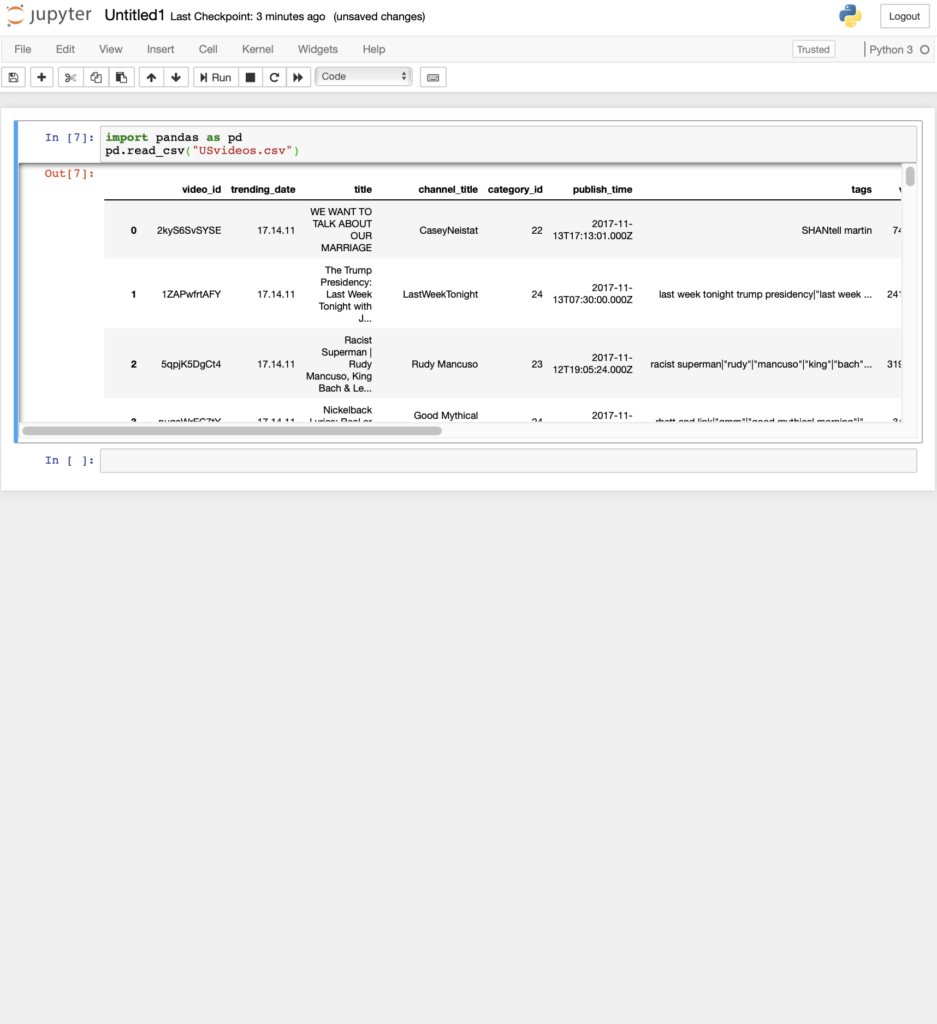
配置した、csvを読み込む
read_csvでいい感じに読み込んで表示してくれる
import pandas as pd
pd.read_csv("USvideos.csv")
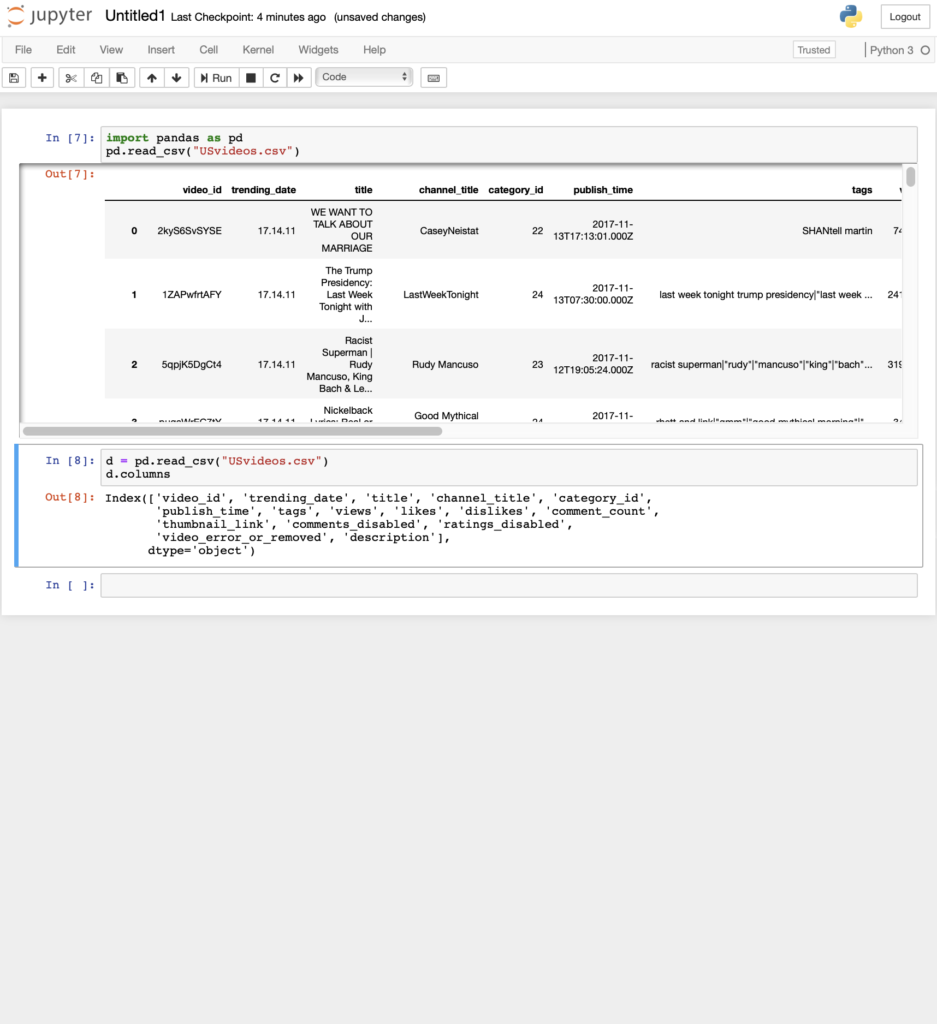
あとで使うので、変数に格納しておく
d = pd.read_csv("USvideos.csv")
columns一覧を表示するにはこちら(唐突)
d.columns
jsonを読み込むにはread_jsonでOK
pd.read_json("US_category_id.json")
読み込んだデータをグラフ化する
pandasで読み込んだデータをグラフで描写するにはmatplotlibを使う
terminalでインストールする
% pip install matplotlib
category_idごとのview数を出してみる
import matplotlib.pyplot as plt
cat_d = d.groupby("category_id").sum().sort_values('views',ascending=False)
cat_d["views"].plot(kind="bar",figsize=(60,10))

csvとjsonのデータを合体させてグラフ化する
このままだと、Categoryが数字なので、何のこっちゃわからない
category_idとCategory名の結びつきは別のjsonデータの方に載っていた
jsonのデータをpandasで読み込む
pd.read_json("US_category_id.json")
![]()
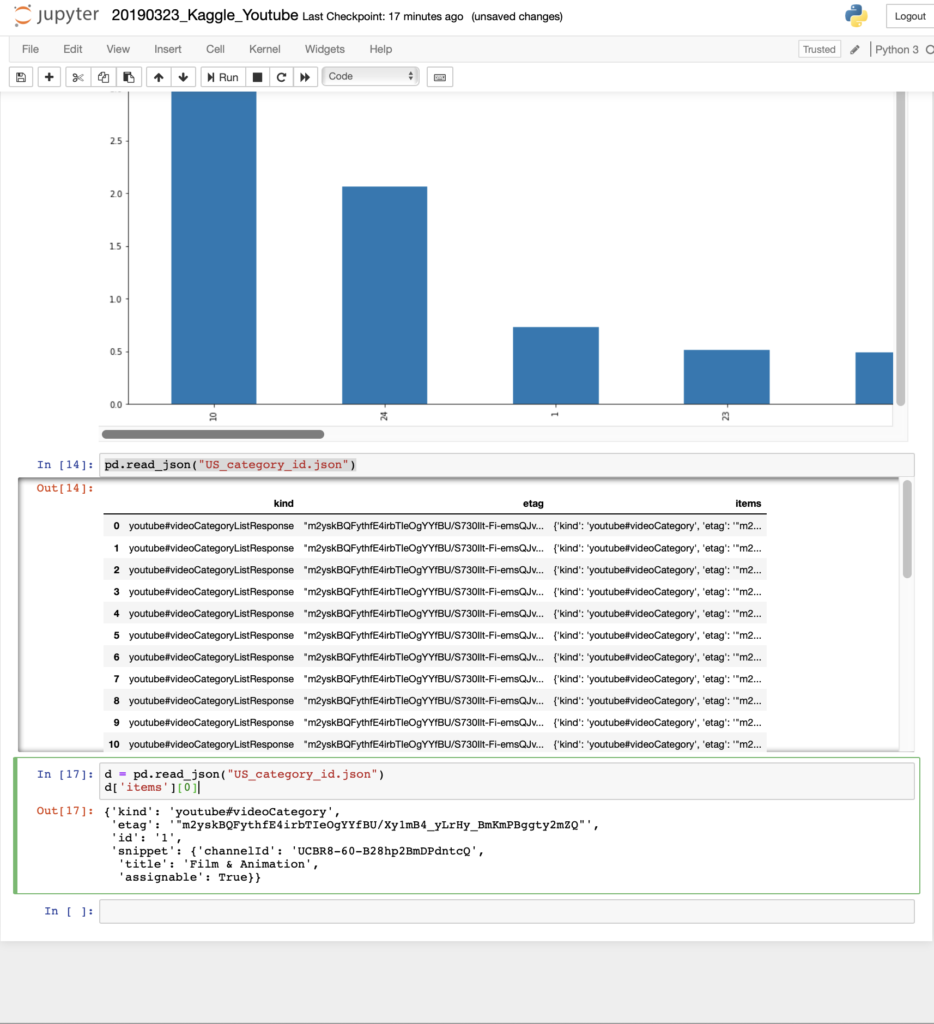
中身を見ると、itemsの中がさらにjson形式で格納されている
d = pd.read_json("US_category_id.json")
d['items'][0]
itemsの中を表で表示してみる
多分、idというのがcsvデータの方のcategory_idで、Category名がsnippet.titleと思われる
pd.io.json.json_normalize(dj['items'])
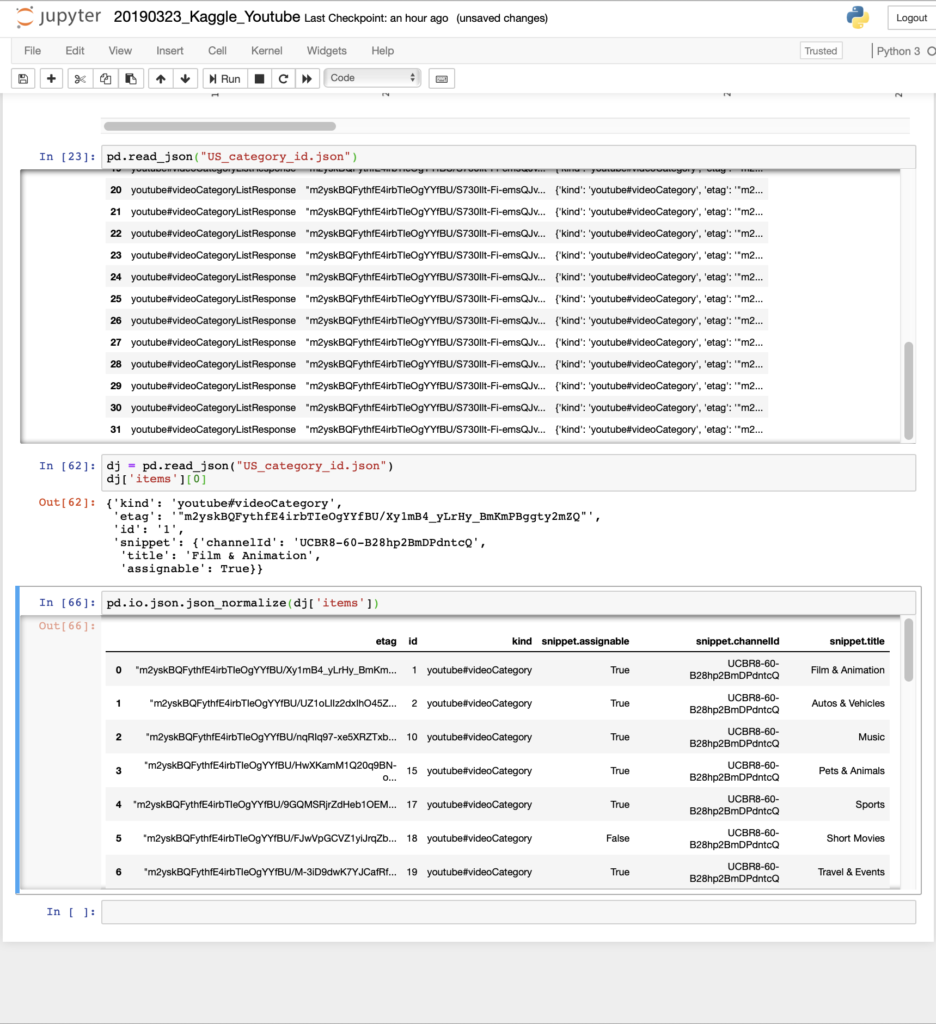
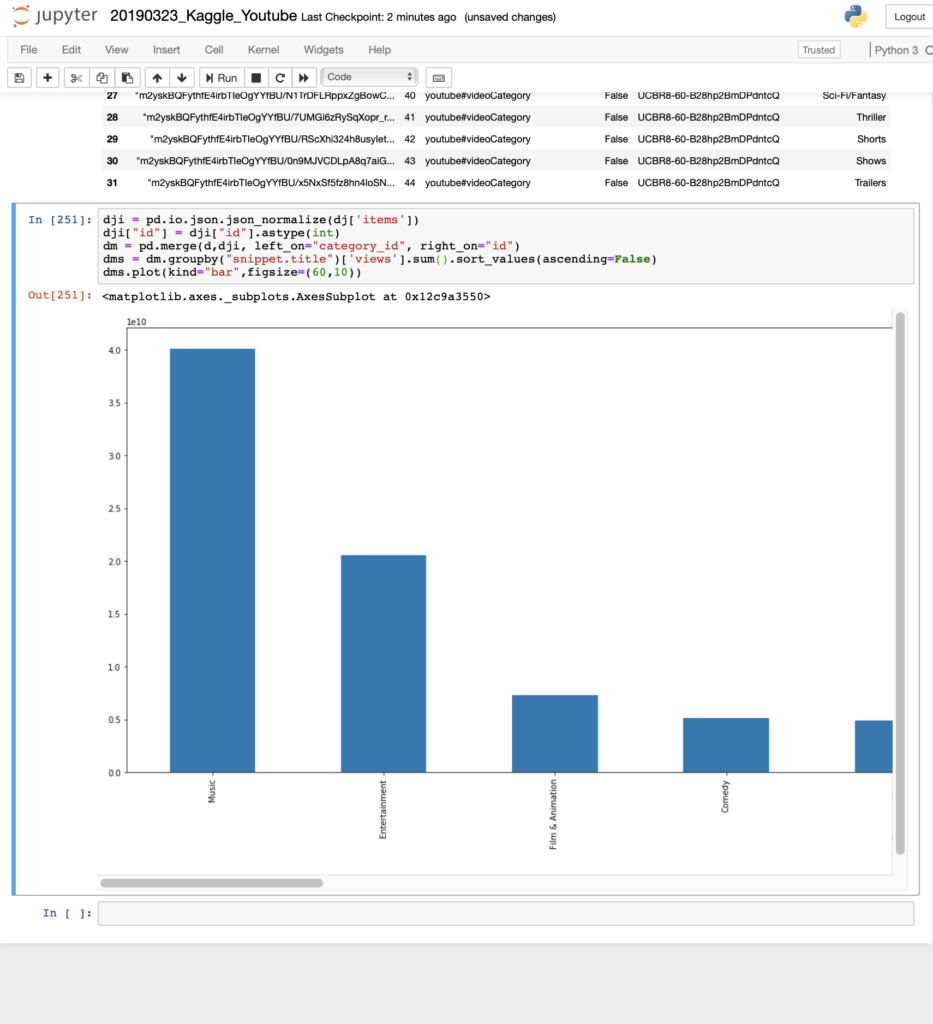
csvデータの方の「category_id」とjsonデータの方の「id」を結びつけて合体させる
dji = pd.io.json.json_normalize(dj['items'])
dji["id"] = dji["id"].astype(int)
dm = pd.merge(d,dji, left_on="category_id", right_on="id")
dms = dm.groupby("snippet.title")['views'].sum().sort_values(ascending=False)
dms.plot(kind="bar",figsize=(60,10))
これでいい感じに表示された