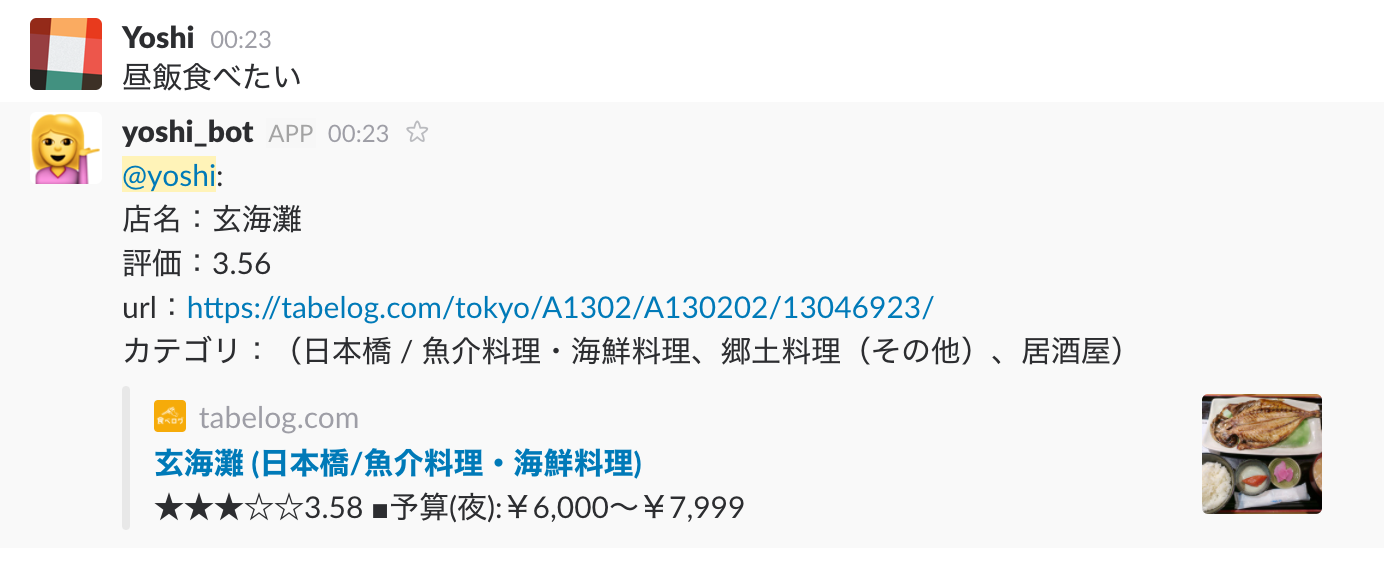
この記事は3年以上前に書かれた記事で内容が古い可能性があります
食べログAPIないのでXPATHを使う
2017-06-11
あれ、食べログってAPI無くないか?ということで習いたてのXPATHを使って食べログの情報を取ってみる。
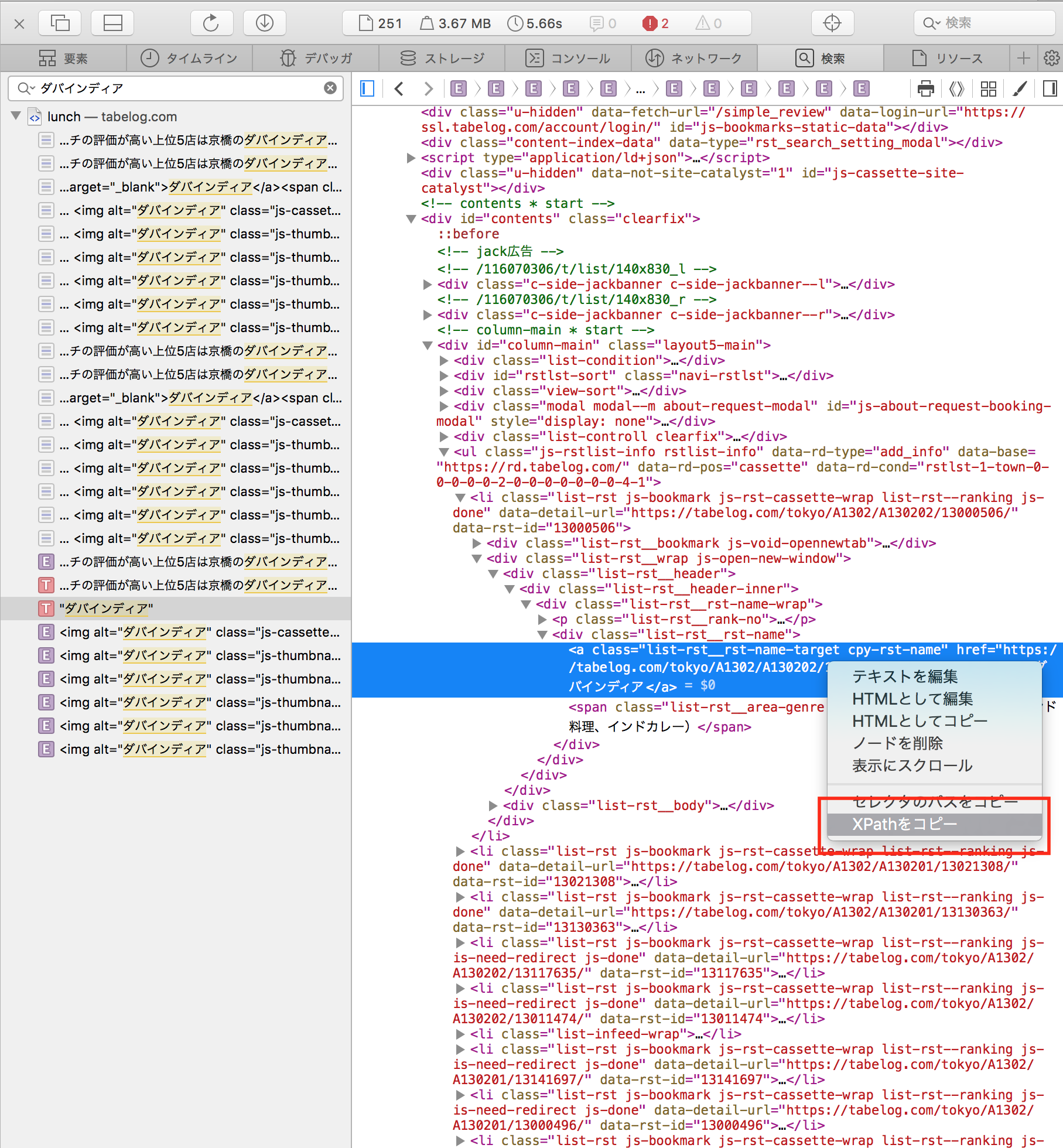
■xpathの取り方
Safariにて「XPATHをコピー」という便利な項目があるので使う
■コード
コードにペタペタ
% cat taberogu.py
import urllib.request as request
import lxml.html
import random
# pickup restaurant
def get_taberogu(url):
ran_num = random.randint(1,21)
with request.urlopen(url) as page:
html = ''
for line in page.readlines():
html += line.decode('utf-8')
doc = lxml.html.fromstring(html)
elem = doc.xpath('//*[@id="column-main"]/ul/li[%s]/div[2]/div[1]/div/div/div/a' % ran_num)
for el in elem:
res_name = el.text
print(el.text)
doc = lxml.html.fromstring(html)
elem = doc.xpath('//*[@id="column-main"]/ul/li[%s]/div[2]/div[2]/div[1]/div/div[2]/p[1]/span' % ran_num)
for el in elem:
res_point = el.text
print(el.text)
doc = lxml.html.fromstring(html)
elem = doc.xpath('//*[@id="column-main"]/ul/li[%s]/div[2]/div[1]/div/div/div/a/@href' % ran_num)
for el in elem:
res_url = el
print(el)
doc = lxml.html.fromstring(html)
elem = doc.xpath('//*[@id="column-main"]/ul/li[%s]/div[2]/div[1]/div/div/div/span' % ran_num)
for el in elem:
res_cate = el.text
print(el.text)
if __name__ == '__main__':
# get till page 5 (yaesu)
ran_num = random.randint(1,5)
result = get_taberogu("https://tabelog.com/tokyo/C13102/C36139/rstLst/lunch/?sort_mode=1&svd=20170611&svt=1900&svps=%s" % ran_num)
■実行結果
% python taberogu_test.py 割烹 嶋村 3.58 https://tabelog.com/tokyo/A1302/A130201/13000499/ (東京 / 割烹・小料理、天ぷら・揚げ物(その他)、丼もの(その他))
■ハマりポイント
lxmlがインストールできずこんなエラーが出るときは
*********************************************************************************
Could not find function xmlCheckVersion in library libxml2. Is libxml2 installed?
*********************************************************************************
色々インストールする(Ubuntu)
sudo apt-get install libxml2-dev libxslt1-dev
これで次は成功する
pip install lxml
■slack
おきまりの、slackに噛ませるとこんな感じ